作者:admin
最后编辑:2026-02-03 22:47:29


![]()
![]()

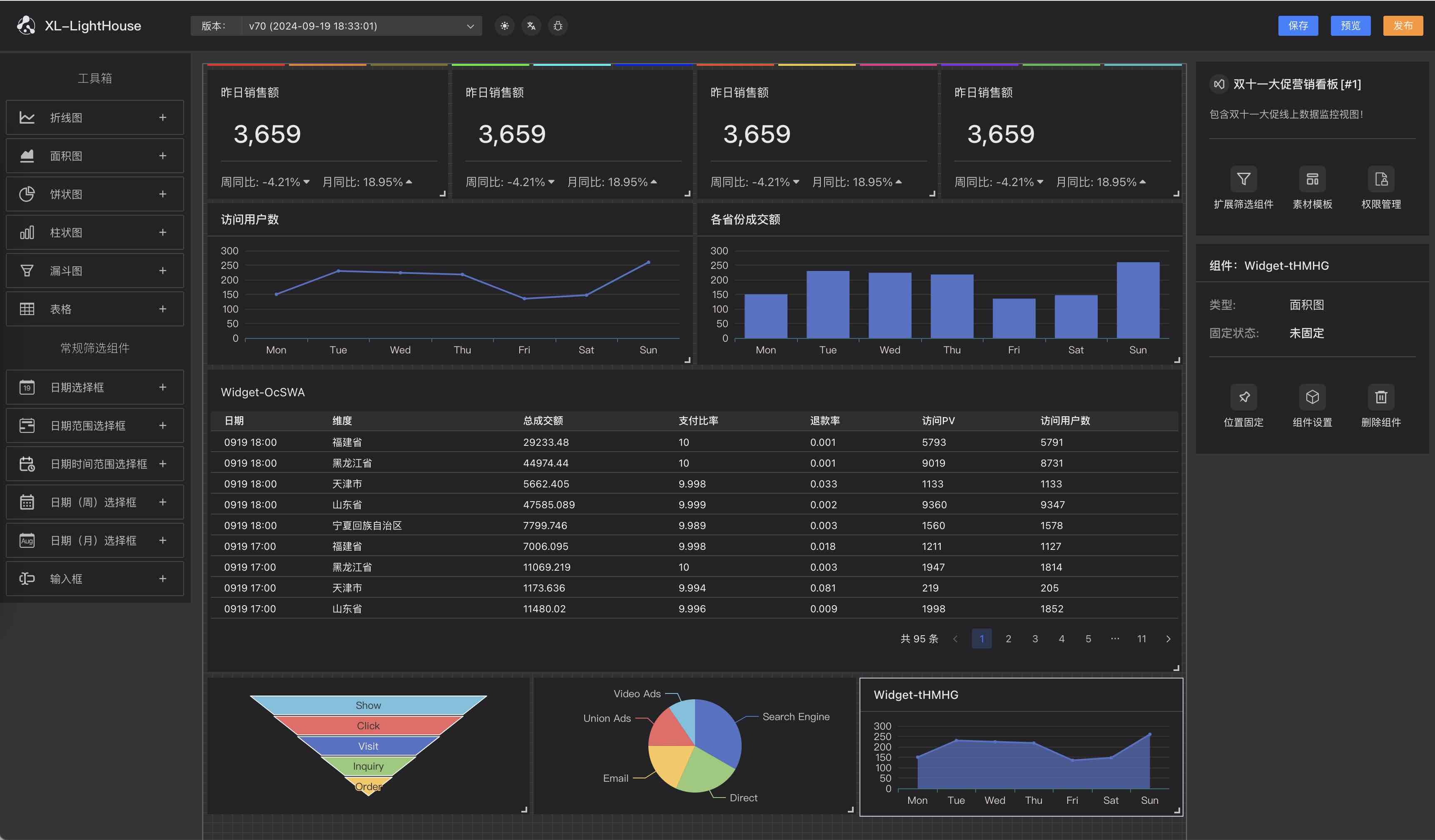
新一代全景式实时业务监控系统,即时掌控业务运行状态,全面提升业务驾驭能力。
并行承载1000万个数据指标,每天处理5000亿条消息。
除大数据版本外,同时支持单机版!
概述

- XL-LightHouse是针对企业繁杂的数据统计需求而开发的一套集成了数据写入、数据运算和数据可视化等一系列功能,支持超大数据量,支持超高并发的实时业务监控系统。
- 目前已涵盖各种流式数据统计场景,包括count、sum、max、min、avg、distinct、topN/lastN等多种运算,支持多维度计算,支持分钟级、小时级、天级多种时间粒度的统计,支持自定义统计周期的配置。
- 内置丰富的转化类函数、支持表达式解析,可以满足各种复杂的条件筛选和逻辑判断。
- 提供了完善的可视化查询功能,对外提供API查询接口,此外还包括数据指标管理、权限管理、统计限流等多种功能。
- 支持时序性数据的存储和查询。
项目特点
- 基于通用型流式数据统计技术实现,依据流式统计运算特点设计,对每一种运算单元进行反复优化,使得每一种运算可以以非常低的成本,无限制复用;
- 可以短时间实现庞大量级数据指标,低成本触达每一个细微的产品模块,而这是Flink、Spark、ClickHouse、Doris、Prometheus、时序数据库等之类技术所不能比拟的;
- 对单个流式统计场景的数据量无限制,可以非常庞大,也可以非常稀少,既可以使用它完成十亿级用户量APP的DAU统计、几十万台服务器的运维监控、一线互联网大厂数据量级的日志统计、一线电商企业的订单统计、也可以用它统计只有零星几次的接口调用量、耗时状况。
- 与同领域其他技术方案不同,XL-Lighthouse擅长应对繁杂的数据统计需求,业务场景越多、数据指标需求越多,XL-LightHouse的优势就越明显;
- 有完善的API,支持高并发查询统计结果;
- 支持数据自动备份、可以一键导入历史数据、可以方便执行集群扩容/缩容;
- 前端基于最新版ArcoDesign(React版本)开发,页面清爽大气,操作体验良好;
- 轻量级使用、部署运维和数据接入不需要大数据相关经验,普通工程人员即可轻松驾驭;
可以用来做什么?
可应用在企业生产众多环节,面向企业至上而下所有职能人员使用,以电商企业来说:
- 可以为企业决策层提供其关注的平台交易额、交易量、下单用户数、订单平均金额、人均消费金额等指标;
- 可以为产品经理提供其所负责产品模块的pv、uv和点击率等指标,只要有业务需要,xl-lighthouse可以计算app内每一个按钮、表单、列表、icon、搜索框等的用户行为统计指标;
- 可以为运营人员提供关注的拉新用户量、各访问渠道用户量、站内各个广告位的点击量、点击用户数、点击收益等指标;
- 可以为开发人员提供其关注的接口调用量、异常量、耗时情况等指标,可以辅助进行压力测试;
- 可以为算法工程师提供其关注的模型训练时长、模型上线后的效果评测等指标,可以辅助进行ABTest;
- 可以为运维人员提供其关注的是线上集群的CPU、内存、负载状况、IO等监控指标;
- 可以为UI设计师提供其关注的不同设计方案的点击转化对比情况;
- 可以为数据分析师提供全面的数据指标更准确判断业务短板、业务走势、辅助决策层有针对性制定营销计划;
- 可以为销售主管提供其关注的每个下属的营销电话量、营销平均通话时长等指标;
- 可以轻松实现对各类复杂业务逻辑各主要环节的数据监控,及时发现问题并辅助问题排查。
- 可以快速建立数据指标之间的交叉验证体系,轻松佐证数据指标的准确性。
针对不同业务领域实现相应的指标需求:
- 可面向物联网、工业互联网、车联网、智能制造、现代农业、智能工厂、智能交通等众多场景实现各类科技设备相关数据指标统计和运行状态监控;
- 短视频App关注的某个视频的播放量、点赞量、评论量、完播率,直播间的访客量、停留时长、刷礼物的数量;
- 即时通信服务所关注的聊天消息量、消息送达时长、日活跃用户,音视频通话相关的丢包率、网络延迟情况;
- 游戏领域所关注的登录用户数、游戏对局次数、英雄出场次数、游戏对局时间、游戏丢帧率;
- 房产类App关注的各个城市各片区每天房源上架量、下架量、涨价量、降价量;
- 交通领域关注的各城市的各条道路的车流量、人流量;
- 建筑领域关注的各城市的每栋建筑的承压健康情况;
- 水利领域关注的每条河流每条河段的水温、水质、水位、水流速度等情况;
更多场景:
单机版本
除大数据版本外,同时支持单机版。单机模式成本低廉,最低配置只需一台4核8G的云服务器。
适用场景:
- 面向中小企业或中小型业务团队使用;
- 面向"用完即弃"的使用场景;
有时候对数据指标的需求,往往只在某个特定阶段。比如:新接口上线要进行接口的压力测试、性能优化;线上业务出现数据异常问题需要排查;数据库读写压力突然暴涨,需要确定异常请求的来源等等, 对于此类场景,流式统计可以起到至关重要的作用。但这类场景一般不需要持续很长时间,可能两三周甚至两三天。这种情况可以使用单机版本,一键部署,轻量级使用,问题排查完,删除即可!
- 用于初步体验XL-LightHouse或作为二次开发的联调测试环境;
日常运维
快速上手
项目介绍
项目地址
- Github:https://github.com/xl-xueling/xl-lighthouse
- Gitee:https://gitee.com/xl-xueling/xl-lighthouse
- 文档地址:https://dtstep.com/
功能预览
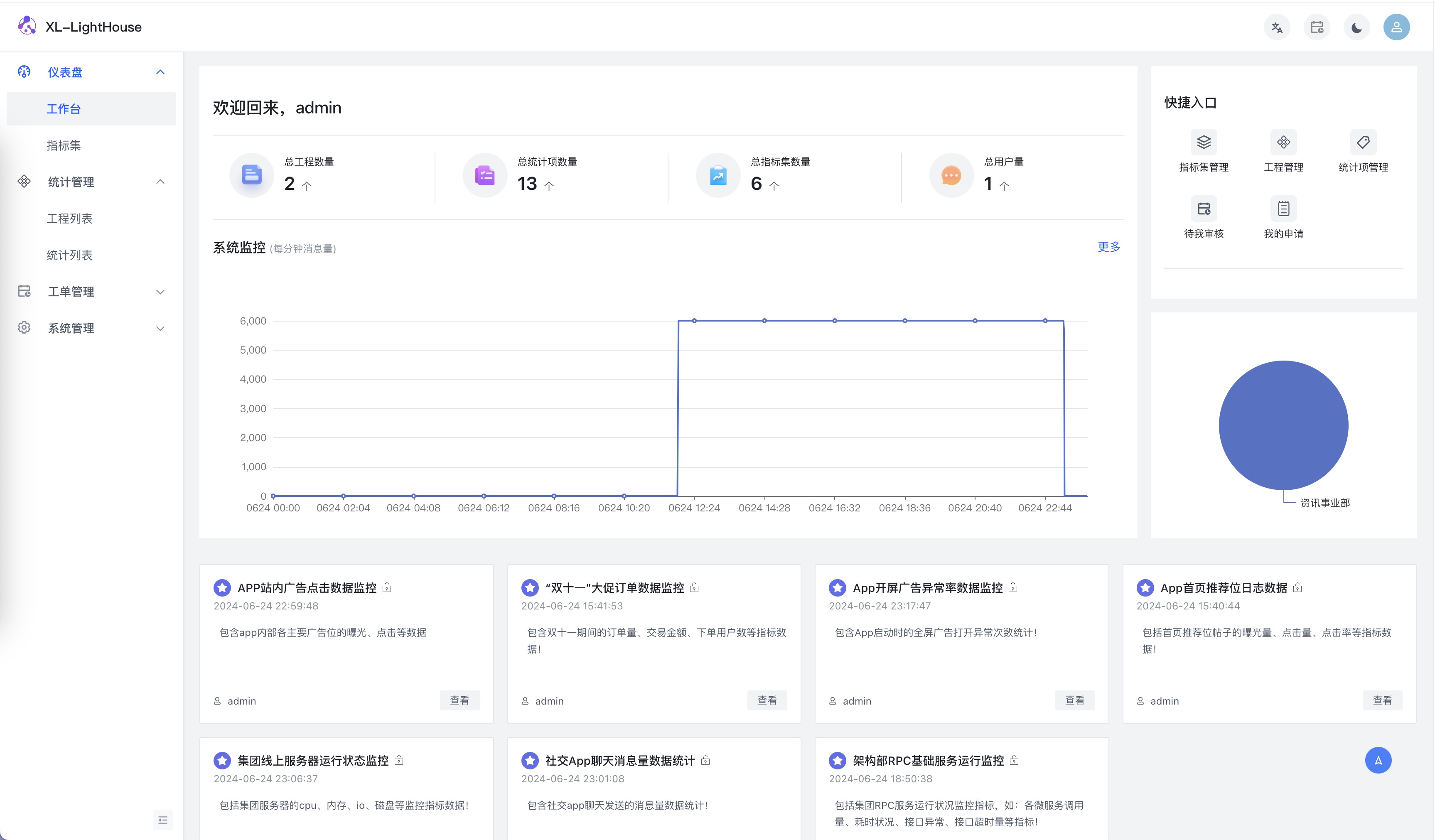
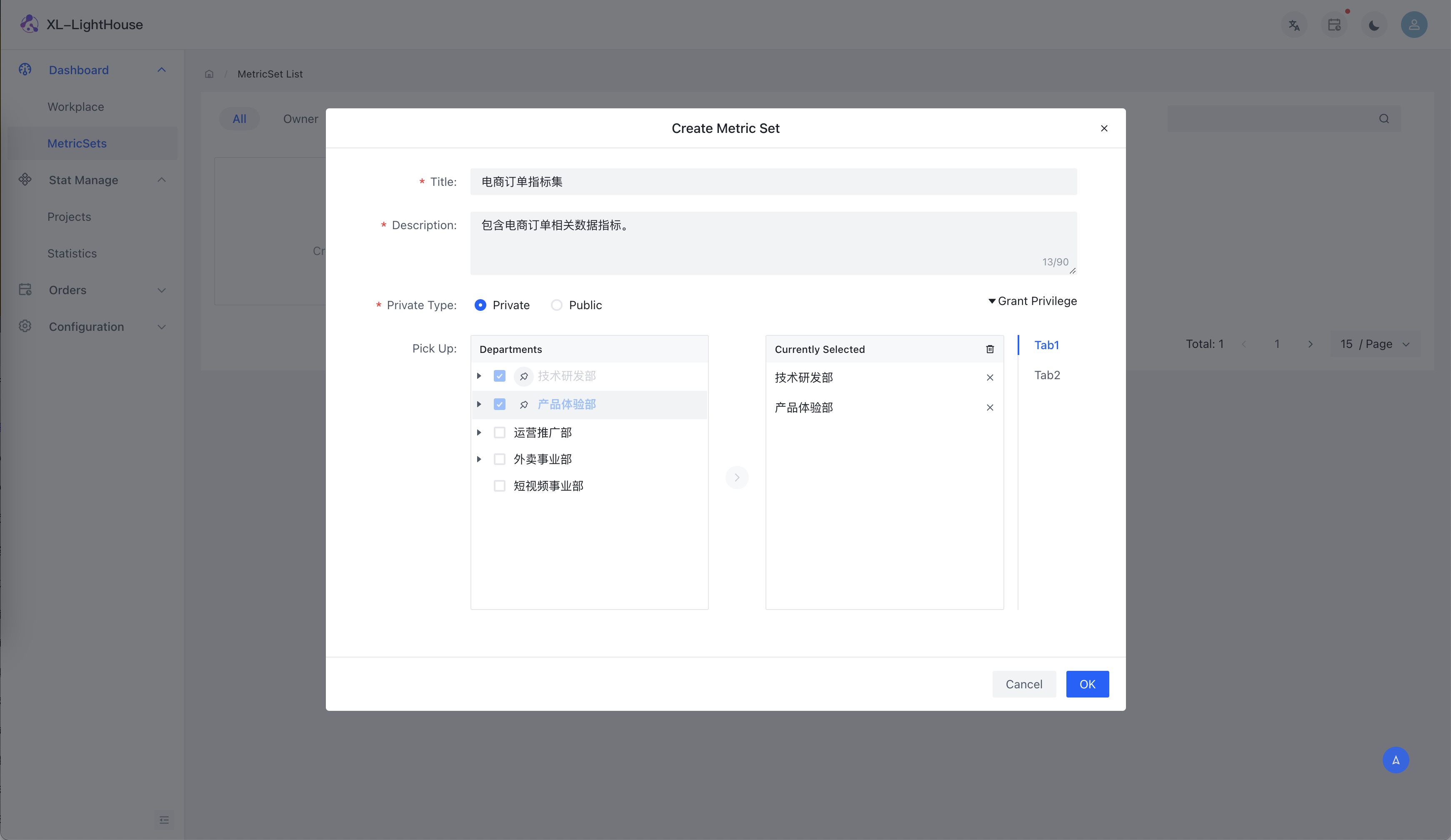
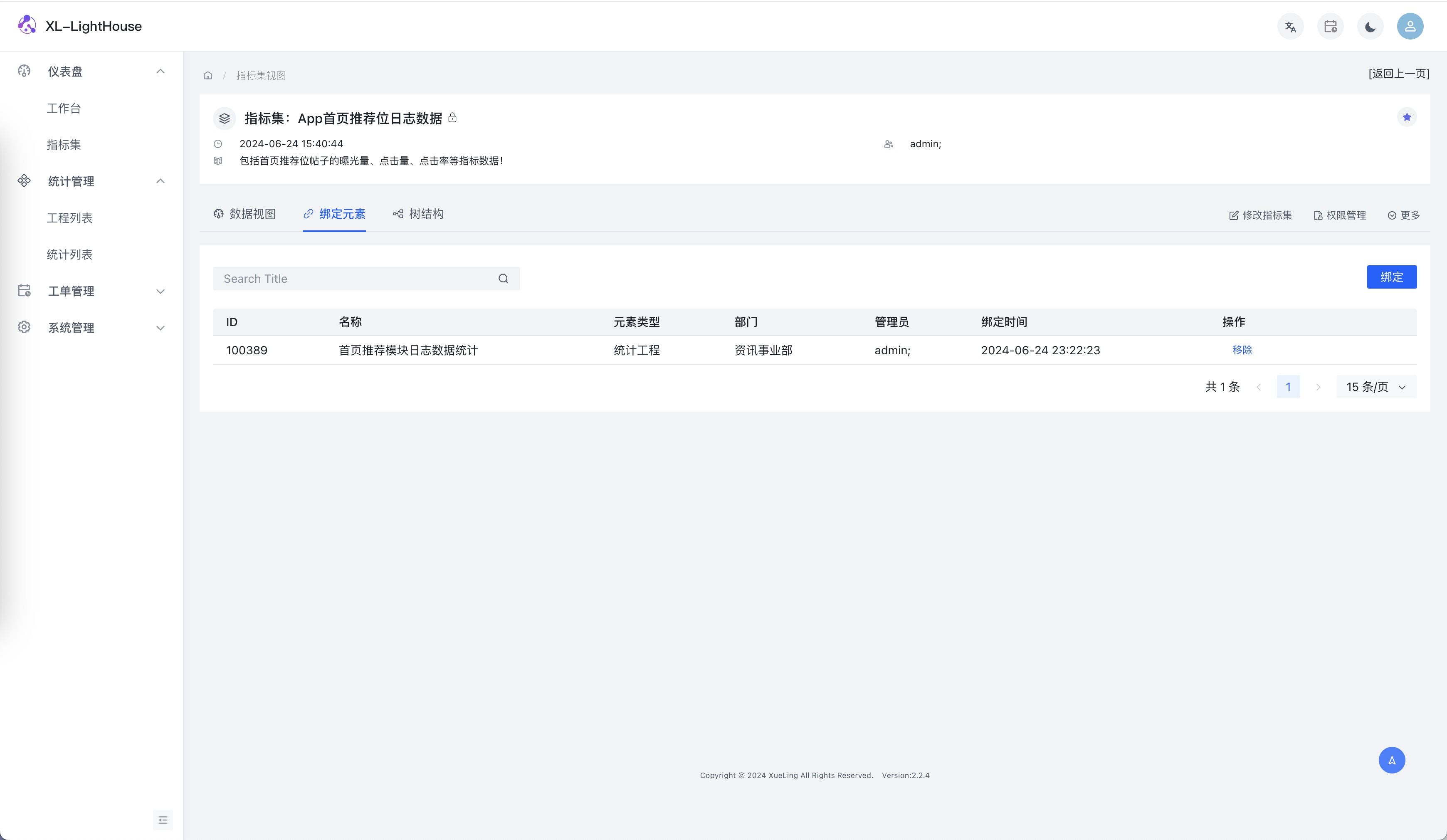
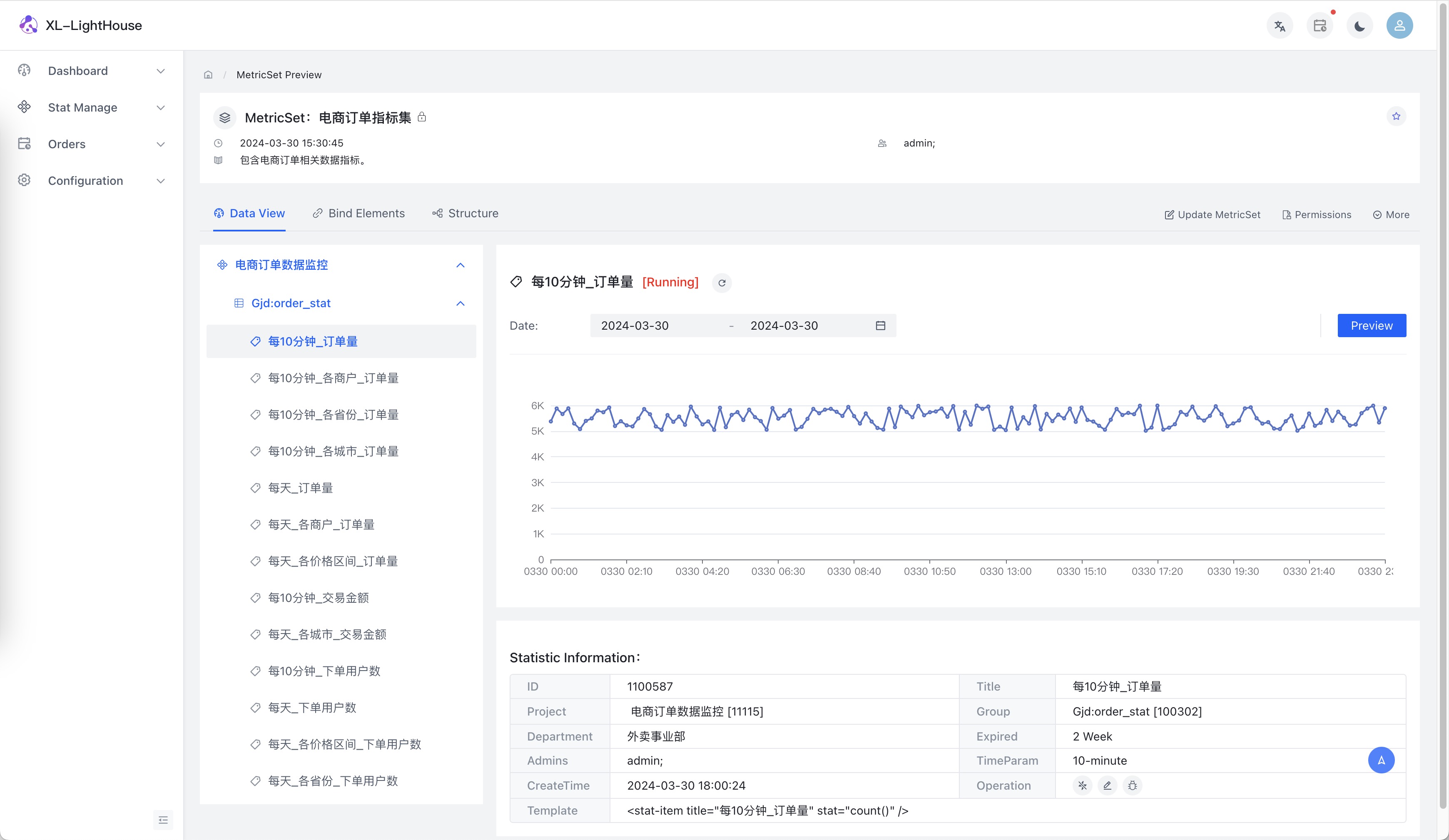
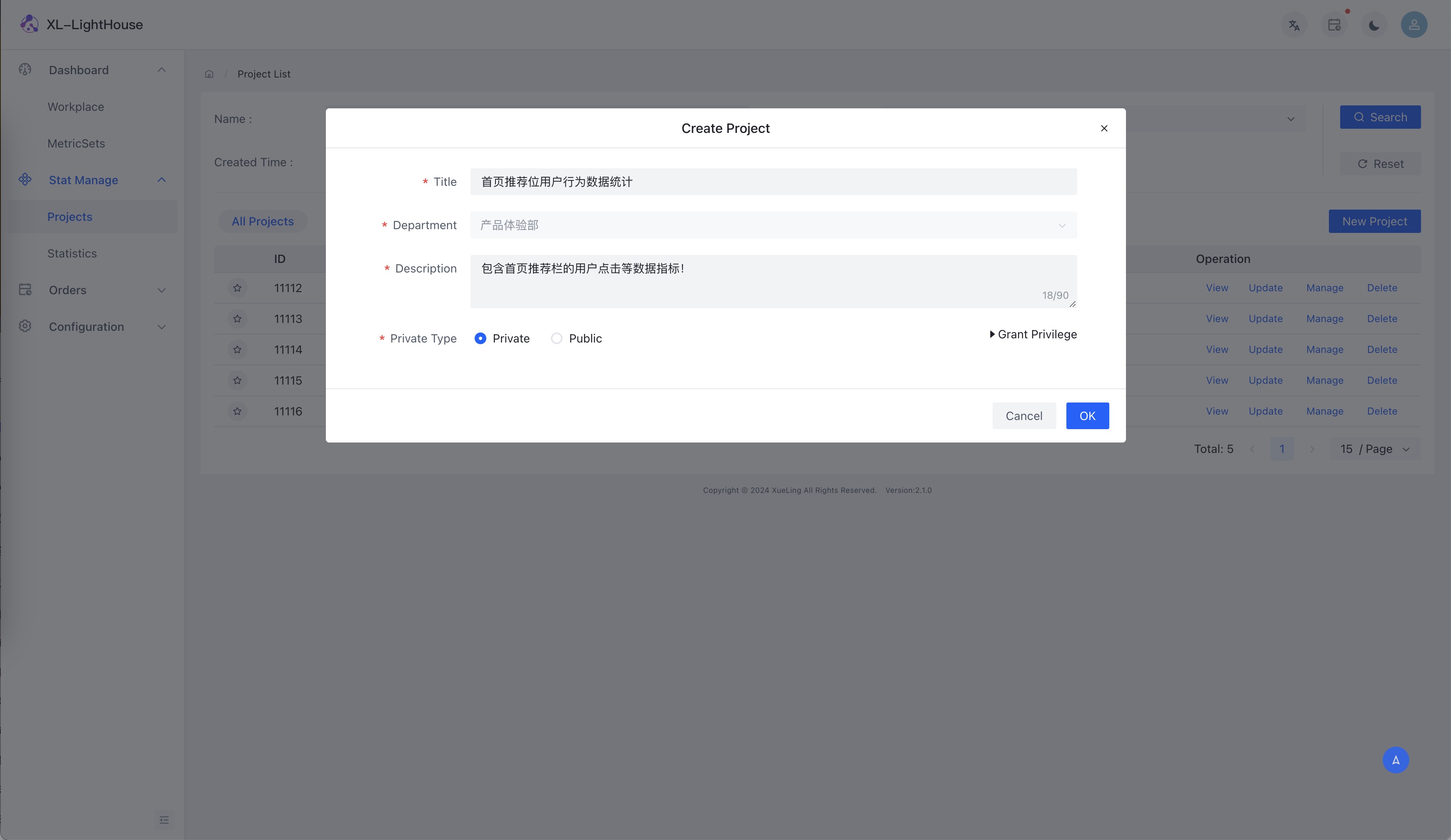
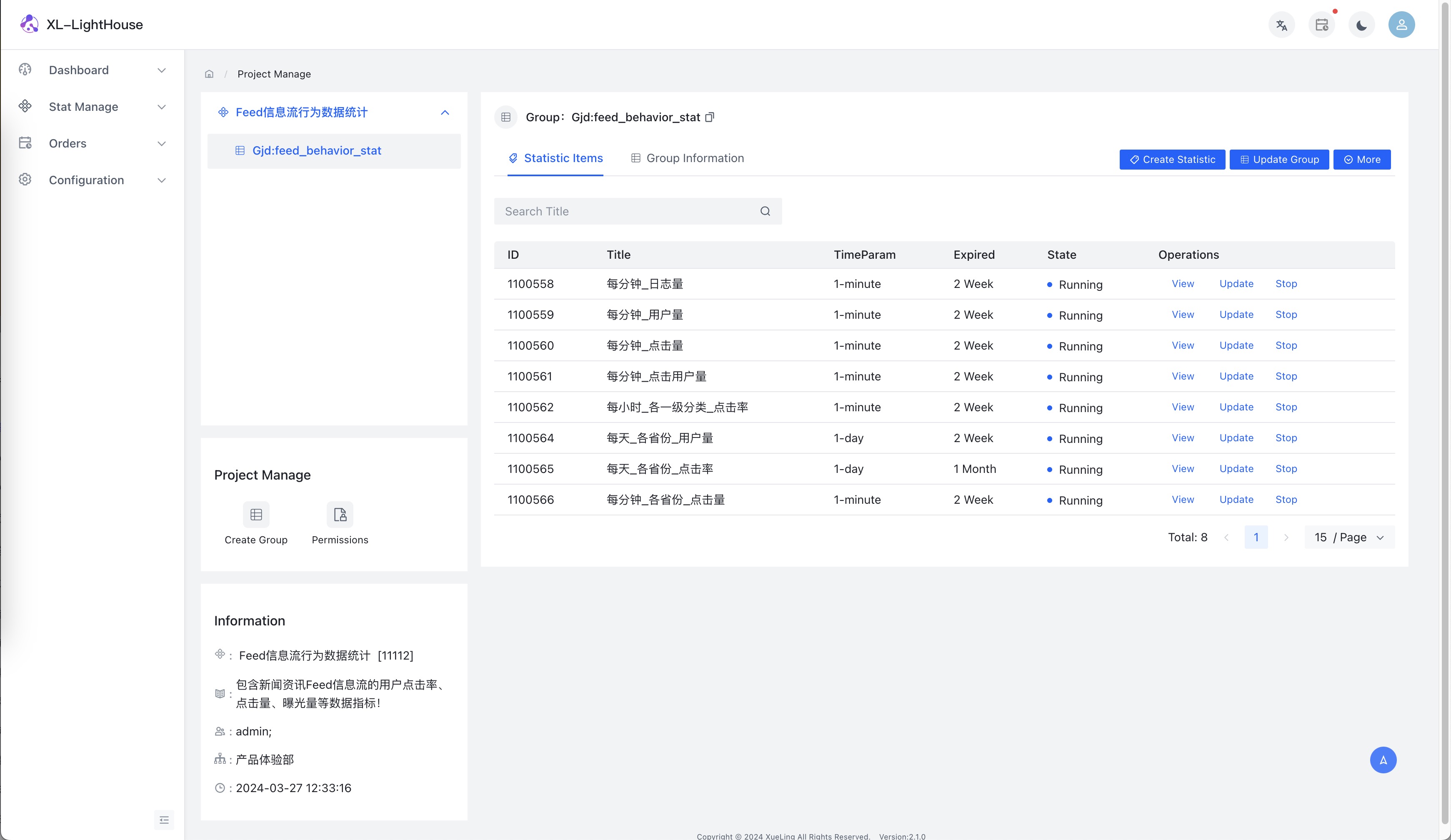
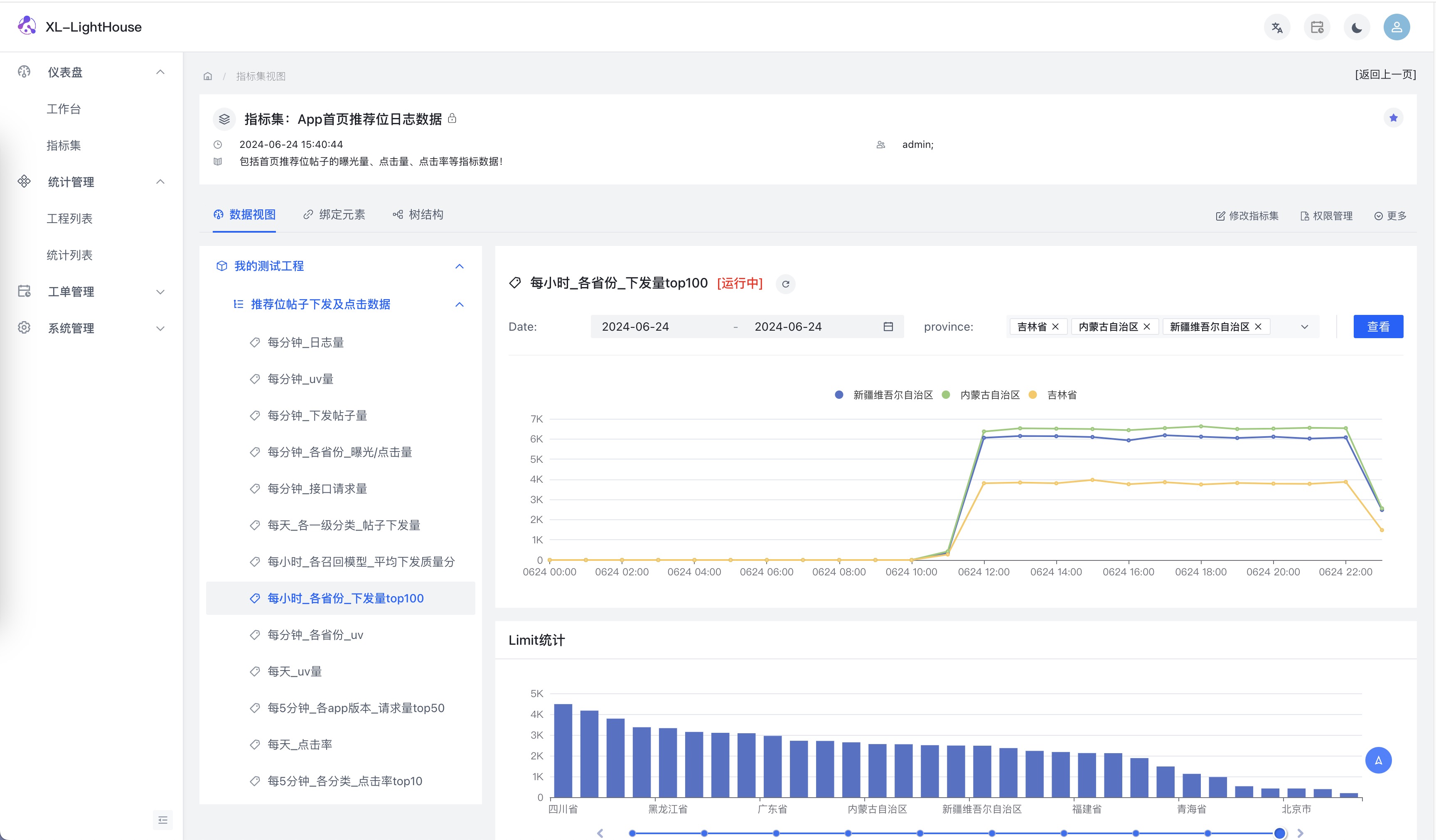

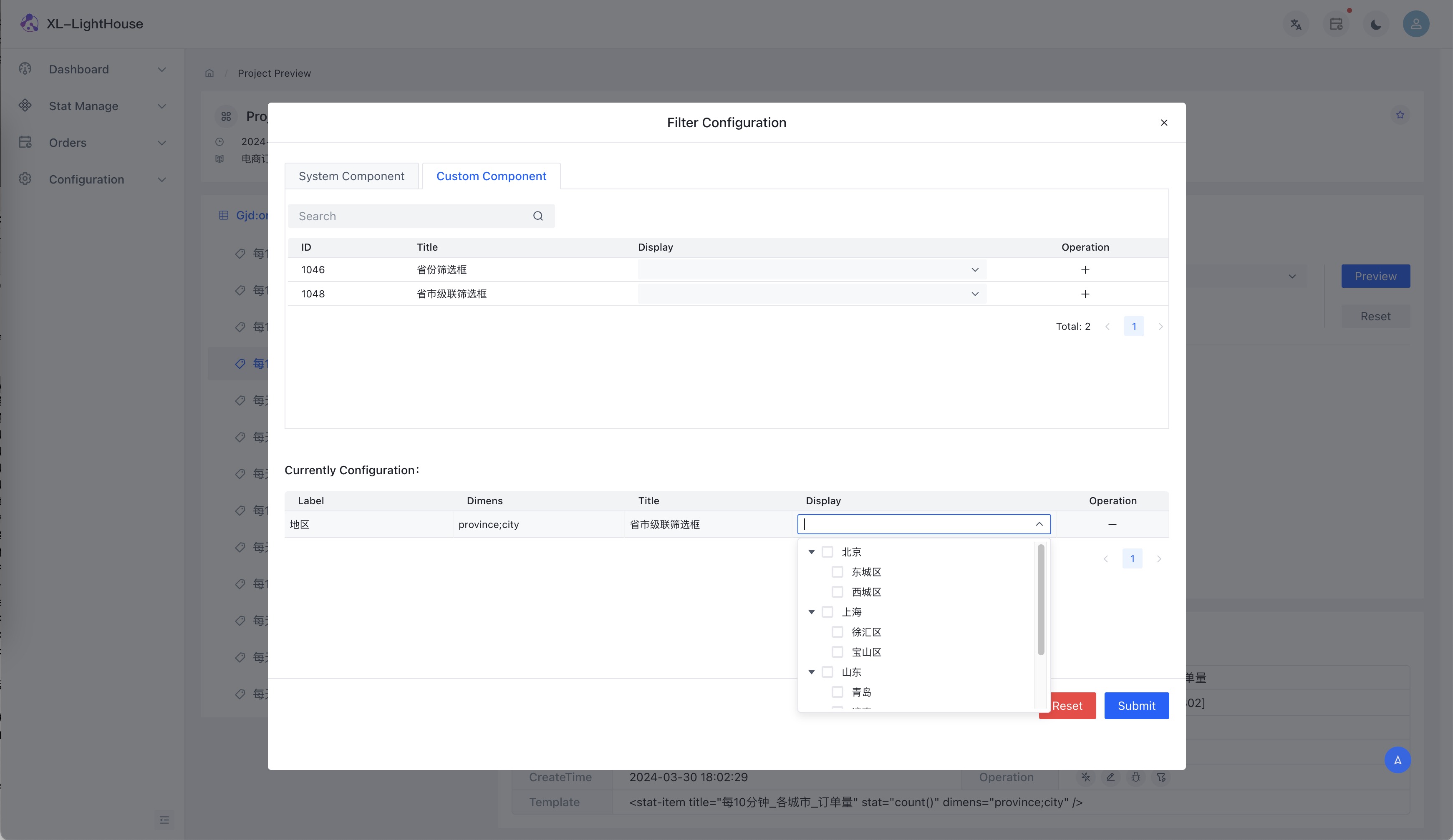
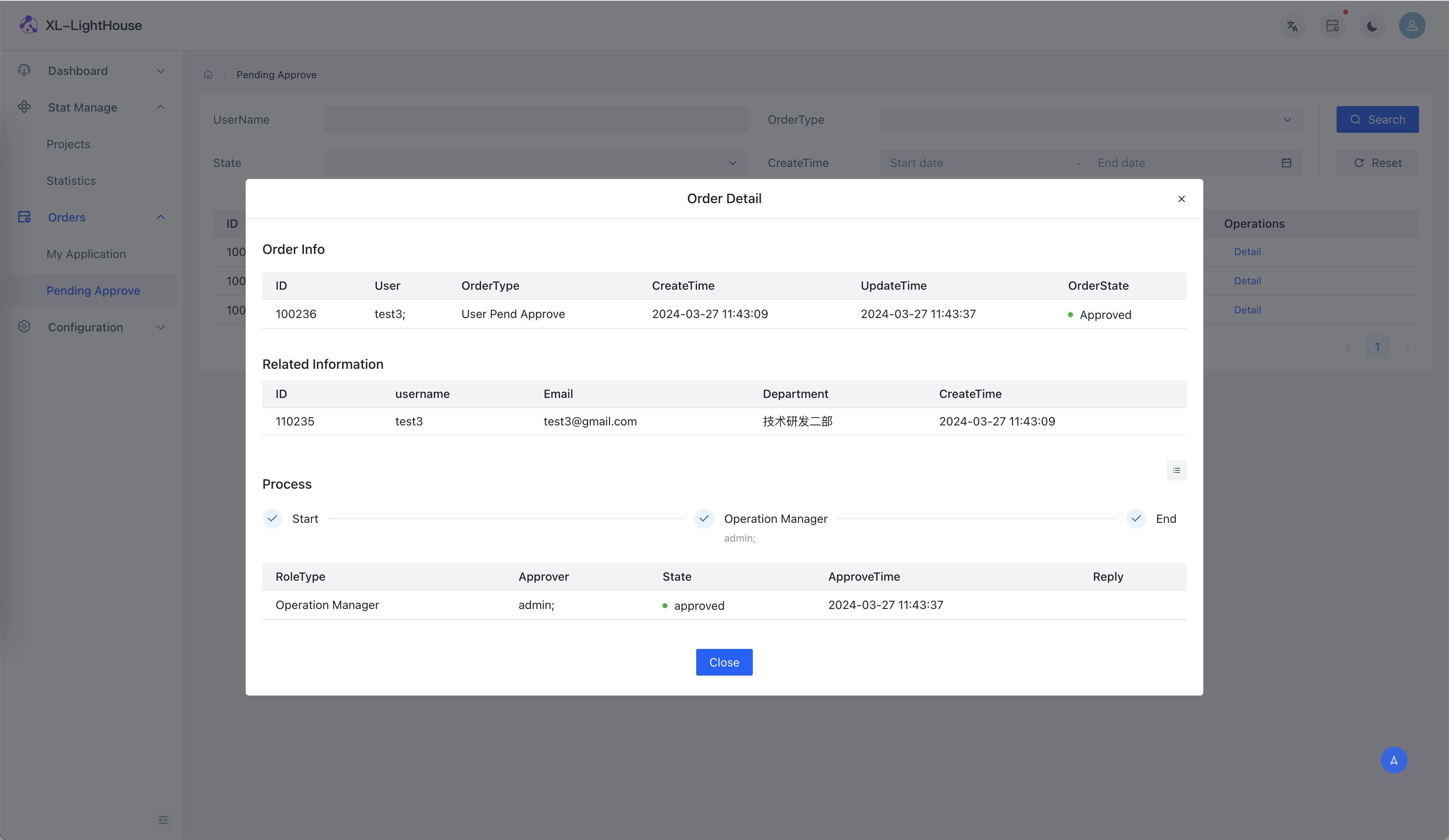
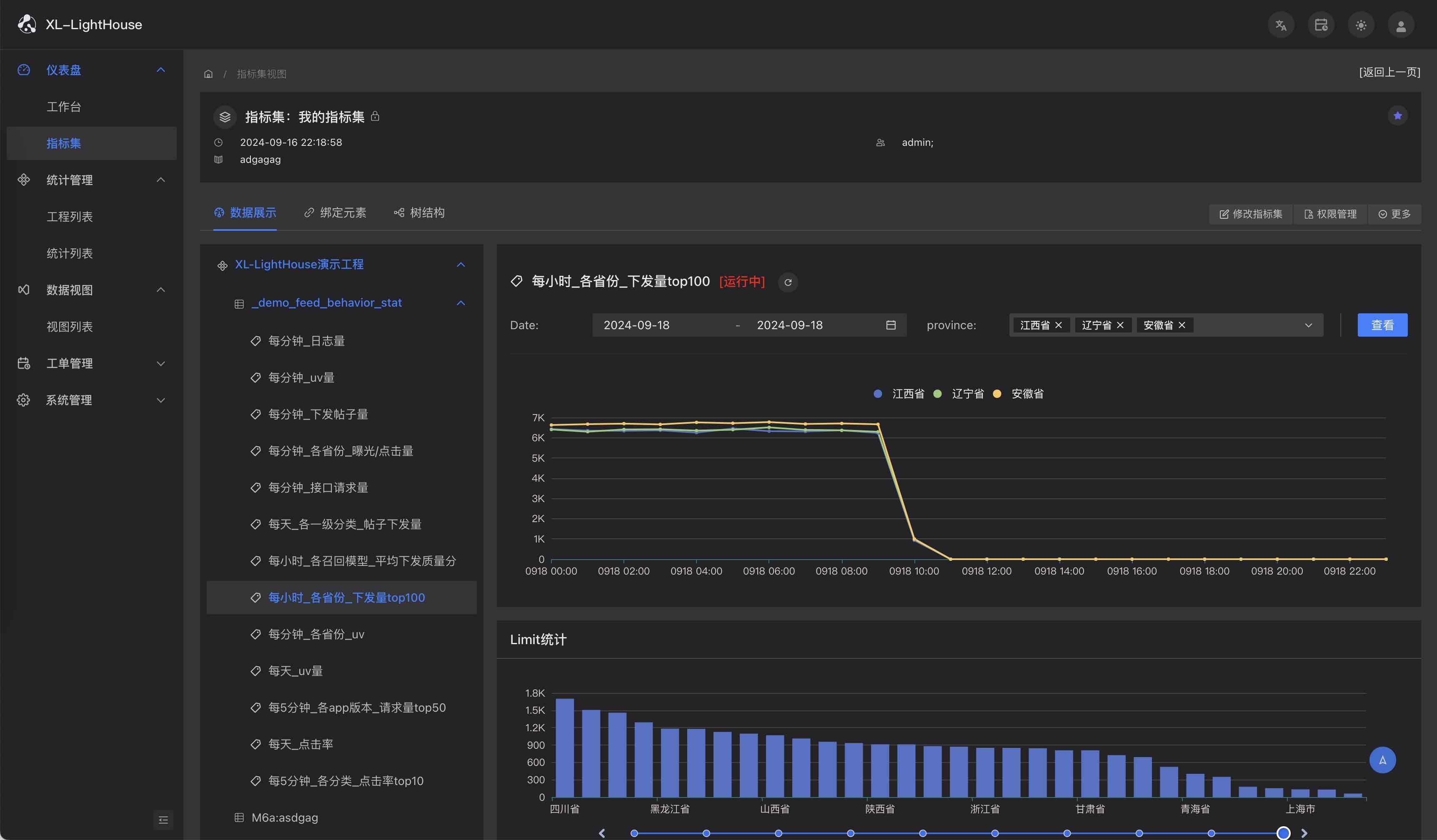
商业版本新品发布、免费提供,可联系开发者获取