实用技巧:排查数据异常/数据波动问题,该如何下手?
前言
在我做开发的这些年,让我很头痛的一类问题,不是线上故障,而是数据异常,不知道有没有程序员跟我感同身受。
大多数的服务故障都有较为直观的异常日志,再结合产品表象,相对排查起来还有迹可循,但数据异常的原因就太多了,很多时候连报错日志都没有,排查起来简直无从下手。
在一个微服务、分布式、前后端分离等概念热火朝天的年代,虽然给身为程序员的我们带来了很大便利,但也同时带来了很多苦恼。分工更加明确,减少了很多工作量,我们大部分的时间和精力专注于自己所负责的模块即可。
本来一切都很美好,但是在排查一些数据异常类问题时却遇到了麻烦!
业务的底层逻辑错综复杂,一个接口的响应需要经过三四个微服务的协同处理这非常正常,甚至涉及七八个以上的微服务都不罕见。 不少服务是不同的人员,甚至是不同部门的人员在维护,这给排查带来很多不便,那该如何快速定位问题呢?
行业目前的现状
如果自身服务有异常日志,一眼就能确认问题还好说,但如果自身服务一切正常,那排查起来可得费老大劲了。
这种数据异常问题,往往是突然发生,打你一个措手不及。很多时候我们本来就有正常的开发排期,时间也比较紧张,突然再穿插一个数据异常排查的事情进来,这就很让我们气愤。 当被产品经理或者部门主管找上门来,总不能跟他说:我的服务没问题,哪里的问题我也不知道!
冷静下来分析,既然是数据异常类的问题,不少朋友可能会说,还能咋办,跑数呗!
跑数,说起来简单做起来可不简单,目前各个企业或业务团队的现状大概分为几种情况:
- 1、已经将相关日志格式化后存储到数据平台,可以写SQL查询(困难指数:两颗星);
- 2、日志没有格式化,而是落到了磁盘、HDFS或者其他存储引擎上,需要写专门的Java、Python或MR或Spark等的任务去解析原始日志然后再跑数,如果日志量大一点、日志格式再混乱一点,工作量可不小(困难指数:五颗星);
- 3、可能连必要的日志都忘了打印(困难指数:非人力所能及,跑路吧!);
说到这,有些小伙伴觉得:那明白了,知道怎么办了,把日志格式化都写到数据中台里,有问题就写SQL查!!!
我想说的是:too young,too simple!
使用数据中台排查此类问题的弊端
使用数据中台写SQL查询格式化后的日志,困难指数是两颗星,但问题是,这有个前提:得先把日志格式化后写到中台里!关键问题是这步操作并不简单。
企业自建或购买的第三方数据中台大多是OLAP类的数仓/数据湖的解决方案,当然有些企业比较有钱,喜欢用ES来搞。
日志是非结构化的数据,是比较混乱的一种数据结构。一般来说企业的日志数据有两种:一是前端(App/H5/PC)上报的埋点日志,二是后端业务系统自己输出的日志。前端上报的埋点日志还较好一点,起码有用户信息、设备信息、埋点类型等固定参数,此外再加上不同埋点类型对应的自定义参数。
如果数据异常问题只涉及前端埋点日志,企业也已经搭建好较为完善的埋点日志存储和查询平台、并且每种埋点类型的日志都已将关键字段提取后格式化存储了,那这种情况比较理想基本只要写SQL就行了,写SQL看数虽然不够清晰直观,但还是可以凑合用的。不过如果企业的数据中台搭建不够完善或者埋点定义比较混乱的话,那就得写代码处理了。
但前端埋点只涉及用户行为侧数据,而很多业务逻辑处理细节的日志数据就不包含了,这时候就需要基于后端日志来实现。大家都知道通过后端日志排查一些异常信息、链路追踪等问题相对容易, 但是后端日志没有任何规范可言,后端日志类型远远超过前端日志,而且会随时添加、随时删除、随时变更格式。如果想基于后端日志进行统计分析绝对是一段让人痛苦不堪、叫苦连天的经历,如果想把混乱的后端日志写入数据平台再进行统计分析难度超乎寻常的大。
再者来说,从我过往的经验和教训来看,很多时候一份数据并不可靠,关键数据是需要交叉验证的!
我列举两个小例子,你就明白了:
1、服务A调用服务B的接口,数据监控应该加在服务A侧还是服务B侧? 或者服务A与服务B通过消息中间件通信,A将数据写入消息服务,B从消息中间件中读取数据,统计监控应该加在服务A侧还是服务B侧? 准确来说,如果业务比较重要的话,应该两端都加,否则即使对方拿出错误的统计数据来质疑你的时候,你可能都难以辩解!
2、App端有个重要的表单提交功能,如果要统计用户表单提交量,应该用前端埋点的上报量还是后端接口的请求量还是DB的写入量? 有些朋友可能会觉得:这还用说吗,业务数据肯定是以DB写入为准啊。没错,不过如果从服务监控和排查问题的角度来看,如果业务较为重要,三个阶段的数据监控应该都加,也就是表单埋点上报阶段、后端接口被请求时以及后端将表单数据写入DB时!
完善的服务监控体系,在于数据指标之间的互相印证!
说到这里,数据中台的弊端就已经较为明显,我们可以总结一下大概有几点:
- 数据中台接入困难;
- 为了应对查询,数据中台内部需要维护庞大量级的日志数据(前端日志 + 后端日志),给企业带来很大的服务器费用和维护费用;
- 使用数据中台需要随时应对日志的格式、参数变化可能会导致数据中台内字段的变化;
- 日志的结构和参数发生变化后,数据中台内部往往会同时存在相同日志类型,但格式不同的多种数据,这很可能导致统计分析的错误;
- 数据中台很难实现对指定日志类型快速的上下线;
- 使用数据数据中台查询统计数据,需要写大量的SQL,很浪费时间而且数据展示不够直观;
数据中台臃肿笨拙,即便是一线大厂拥有充足的资金和人力也没有可能使用数据中台建立起较为全面的服务监控体系。
所以,不管是写程序还是用数据中台排查此类问题并不能算是一个十分高明的方案,或者说仅仅只是一个还凑合的方案!
我所推荐的方案
现在的产品逻辑、业务逻辑越来越复杂,而数据异常很多时候会涉及企业安身立命的根本,毕竟数据异常很可能会带来直接或间接的经济损失和用户流失!
那还有没有其他更便捷、更清晰、更立体、更周全的解决方案了呢?
有,当然有,这就是我接下来要郑重向大家推荐的:开源通用型流式大数据统计系统XL-LightHouse。
绝大多数朋友应该还没有听说过它,甚至连通用型流式数据统计都没有听说过,那它相比业内目前使用的方案究竟有什么优势呢?
我一直偏执的认为:解决此类问题通用型流式数据统计是唯一接近完美的解决方案!
XL-LightHouse与众不同的特点
- 1、轻量级
XL-LightHouse以通用型流式数据统计为切入点,虽然它是一款大数据类系统,但从使用层面上来说,其实是一个非常轻量级,几乎没有任何使用门槛的系统。你可以一键就将它部署到服务器上,至于如何使用,那就更简单了。
只要在Web页面配置相应的元数据结构、创建统计项,再调用它的API将字段数据上报上来,然后就可以在Web端查看统计结果了。
它的整个使用流程简单到几乎不用看文档就可以完成,相比OLAP那一套笨拙、复杂的接入流程,它简直像张白纸一目了然。如果你部署完成后5分钟还没有弄明白该如何使用,都会让我觉得这个项目还有极大的优化空间!
相比于OLAP类系统它不支持原始数据明细查询、不支持多维度字段随意组合的即席查询。 这与它自身定位有关,XL-LightHouse是流式大数据统计系统,它不希望被任何可有可无的功能影响了它的轻便性和它在流式统计方面彪悍的计算性能,它不希望像OLAP那类系统一样,追求功能的完善,却把自己搞的笨重不堪,用户使用起来也感觉非常不便。 XL-LightHouse竭尽所能期望为用户打造信手拈来的愉悦感和轻松驾驭的畅快感。
- 2、功能强大
XL-Lighthouse在流式统计、数据监控等方面的功能可谓十分强大。
- XL-LightHouse目前已涵盖了各种流式数据统计场景,包括count、sum、max、min、avg、distinct、topN/lastN等多种运算,支持多维度计算,支持分钟级、小时级、天级多个时间粒度的统计,支持自定义统计周期的配置。
- XL-LightHouse内置丰富的转化类函数、支持表达式解析,可以满足各种复杂的条件筛选和逻辑判断。
- XL-LightHouse提供了完善的可视化查询功能,对外提供API查询接口,此外还包括数据指标管理、权限管理、统计限流等多种功能。
- XL-LightHouse支持时序性数据的存储和查询。
元数据字段可以根据需要随意指定,一份元数据下有多少统计项可以随意指定,统计任务上线或下线可以随意指定, 它的架构设计更加贴合流式统计的运算特点,并对每一种运算单元都进行了很多层面的性能优化,支持超大数据量和超高并发,在它的功能范围内你几乎可以随心所欲的添加和管理你所需要的统计指标。
如何使用XL-LightHouse排查数据异常类问题?
归根到底是一句话:在任何你有需要的地方加上流式统计。
比如:
- 可以用它统计一个if/else的分支,每分钟各被执行多少次;
- 可以用它统计一个订单接口,每5分钟有多少人下单和下单总金额;
- 微服务A同时调用微服务B、C、D,可以用它统计每天每个微服务各个接口调用量、异常量和耗时情况,甚至每种错误码的返回次数;
- 可以用它统计,前端上报的数据中某个参数为空的请求占比;
- 可以用它统计一个Feed推荐接口,每小时召回帖子的数量、每种召回模型、ABTest策略、不同的地区、不同的内容分类召回帖子的数量; — 可以用它监控一个KV存储服务,每天数据写入量和每天数据查询量,甚至每个key前缀的写入量和查询量; — 可以用它监控APP的启动耗时,弹窗广告的弹出次数;
- 可以用它统计APP内某个广告的下发量、点击量、点击UV和点击率;
- 可以用它监控一个新闻资讯类APP的内容池每小时各个渠道的新增帖子量;
- 可以用它统计一个社交类APP每天聊天消息、聊天表情、红包的发送量;
- 可以用它统计每天销售额top100的商户列表;
- 可以用它统计任意细粒度、任意维度的数据;
- ......
总之,在它的功能范围之内,你可以根据自己的实际需求随心所欲的创建统计指标!
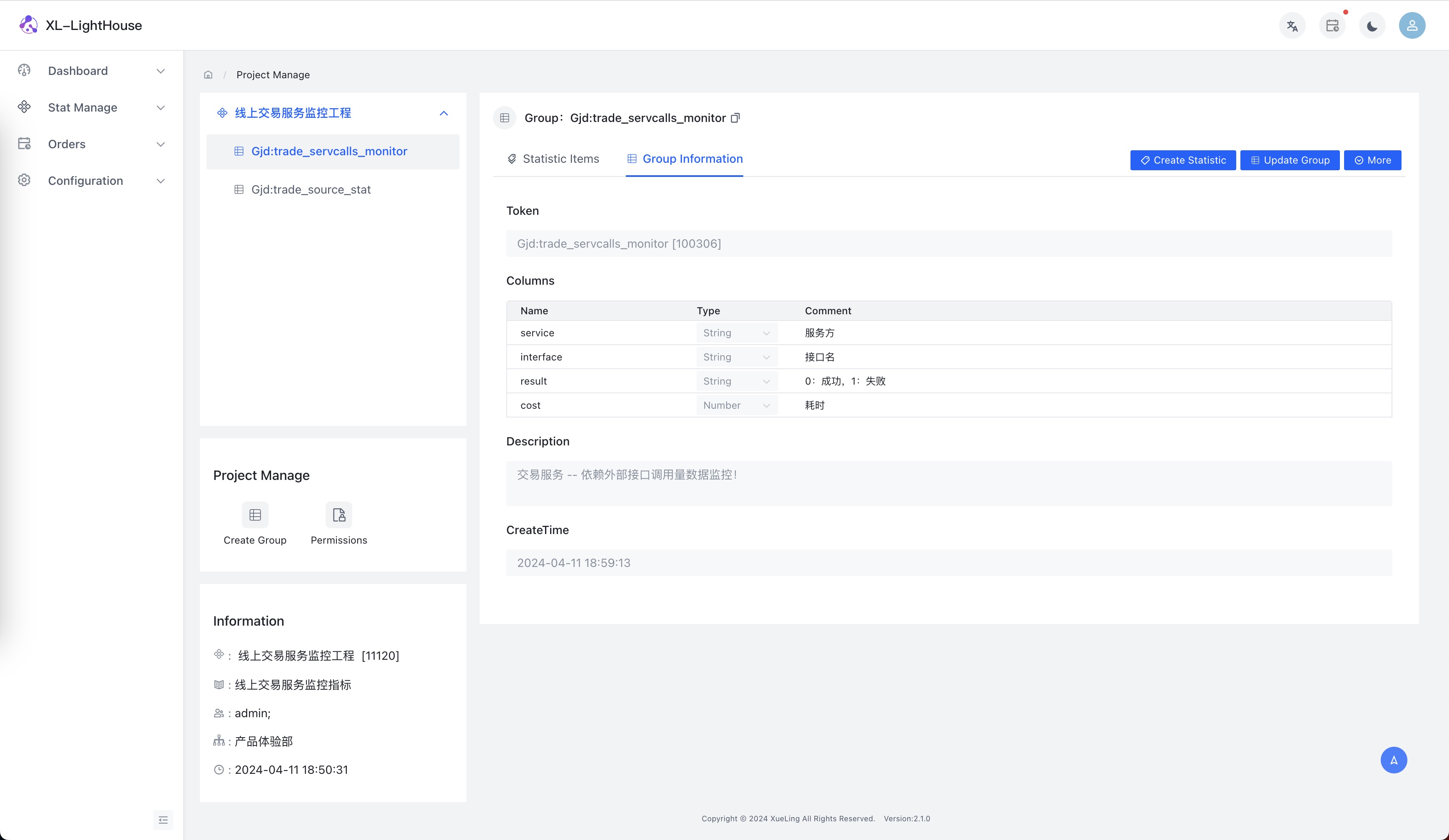
- 示例1:依赖服务接口调用量监控
假设场景:微服务A中要调用其他的服务,我们需要监控各依赖服务的接口调用量、异常量和耗时情况数据。
(有些朋友可能会觉得公司的RPC服务针对各接口的互相调用情况监控数据都已经具备了,为啥还要再监控,我这里只是举个例子,其实本质不一样,公司RPC服务所提供的数据都是定死的一些监控指标,而用XL-LightHouse具有非常强大的灵活性,可以根据自身需求定制!)
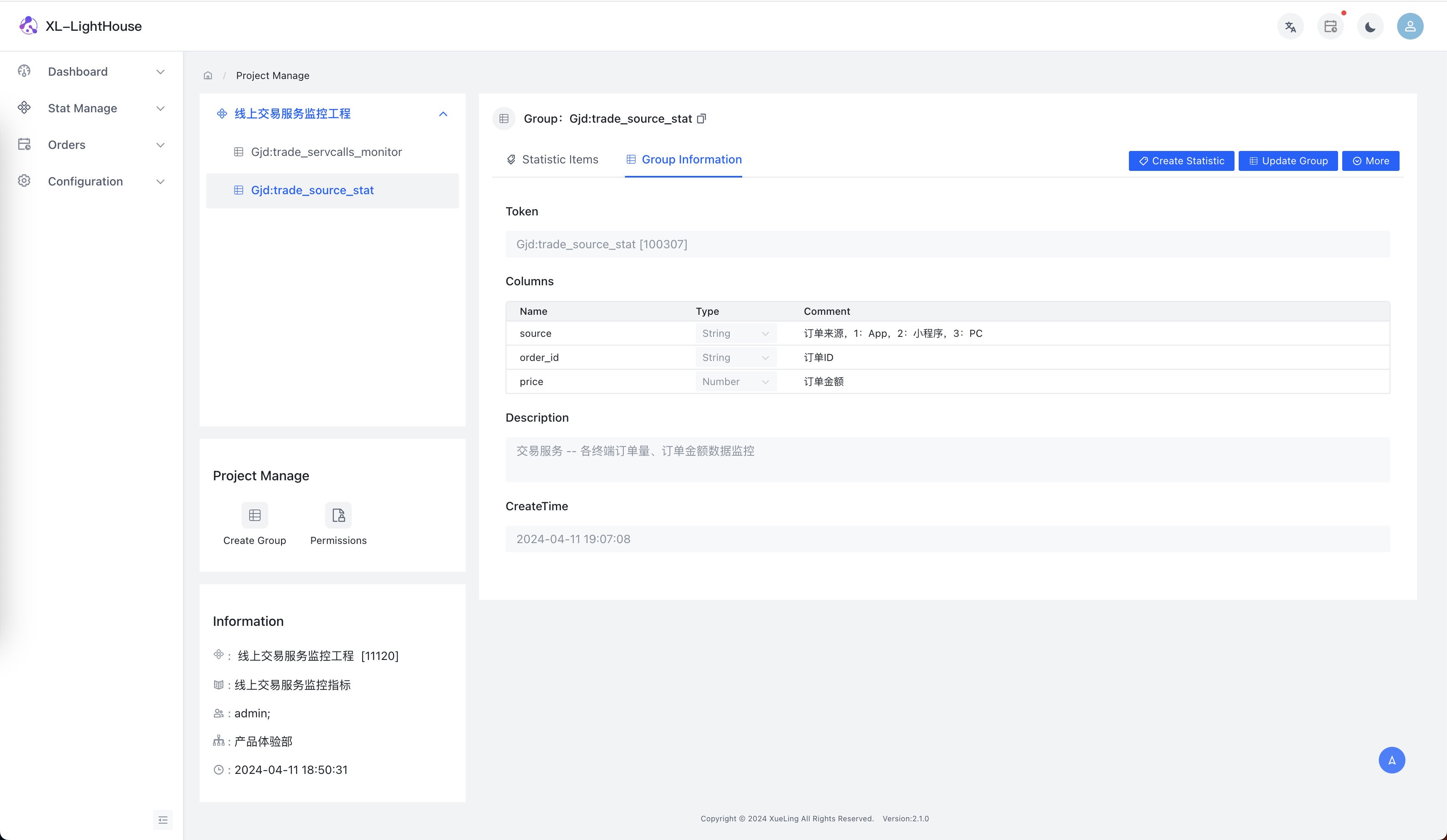
- 示例2:各终端订单量数据监控
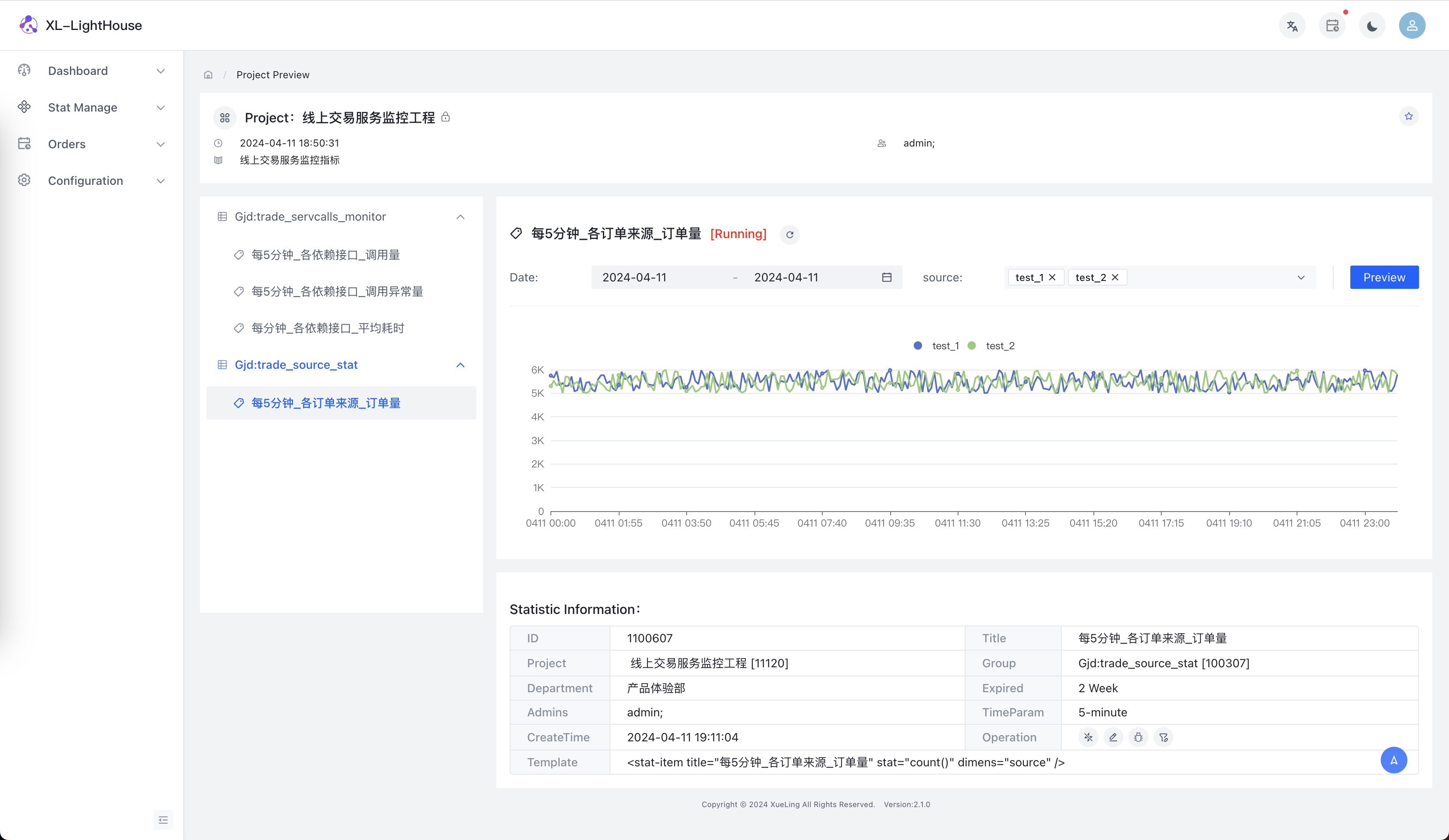
假设场景:交易服务需要监控不同来源下单量的数据。
- 模拟数据接入
public class Testing {
static {
try{
//配置RPC服务地址
LightHouse.init("10.206.6.39:4061,10.206.6.21:4061");
}catch (Exception ex){
ex.printStackTrace();
}
}
@Test
public void testStat() throws Exception {
long t = System.currentTimeMillis();
for(int i = 0;i<10000;i++){
//修改统计组参数值、Token和秘钥
Map<String,Object> map = new HashMap<>();
map.put("source", ThreadLocalRandom.current().nextInt(3));
map.put("order_id",RandomID.id(3));
double price = ThreadLocalRandom.current().nextDouble(1,9999);
map.put("price",String.format("%.2f", price));
LightHouse.stat("Gjd:trade_source_stat","g2BjBuC0g4euWcMzqQXAAlKFcIBPbexQNLovqK9z",map,t);
}
System.out.println("send ok!");
Thread.sleep(30000);
}
}
- 查看结果
担心代码侵入怎么办?
XL-LightHouse对外提供JavaSDK,如果是Java类系统可以在自己的服务中直接调用API。
有些企业的服务并不是基于Java语言开发或者本身不想在使用时有太多的代码侵入该怎么办?
很简单,只要再额外部署一套Kafka或者其他的消息组件,自身服务将相关参数数据写入到消息组件中,然后在消费消息数据时调用xl-lighthouse的sdk就可以了,这套消息服务和消费逻辑可以企业内部共用。
结束语
线上服务监控体系可以根据实际需求陆续创建,等你将监控体系建立完备,这将使你对线上服务的驾驭能力得到空前的提升,五分钟内定位数据异常问题绝非信口开河,每次线上数据异常都是展示你能力的绝佳机会,升职加薪在向你招手~
本文可以随意转载!